house price - 1 - 파악

3년 전에 Kaggle의 House Price Prediction 프로젝트를 진행했었다.
지금도 마찬가지지만, 그때도 높은 레벨의 스킬을 가지고 있지 않아서 이런저런 것들을 참고하면서 어떻게든 해보려고 발버둥쳤었던 기억이 있다.
공부 하는 김에 과거에 대한 기록을 다시 보는 것도 좋은 시간이 될 것 같아, 정리해본다.
가장 먼저, Feature들을 확인해줬다.
# train과 test 데이터 세트 불러오기.
train = pd.read_csv('./train.csv')
test = pd.read_csv('./test.csv')
train.info()
엄청 많은데... 이때 당시에 사전 같은 걸 만들어서 해당 Feature들이 어떤 것을 의미하는 지에 대해서도 분석하려 했었다.
의미가 없는 행위는 아니고 나중에 결측치들을 때려넣는 등 데이터 전처리 과정에서 나름 유용하게 활용된다.
본격적으로 상관계수가 조금 높은 애들만 따로 분류해서 해줬다.
# train에서 상관계수가 0.5 이상인 피처들 추출하기.
corr_house = train.corr()
top_corr_features = corr_house.index[abs(corr_house["SalePrice"])>=0.4]
top_corr_features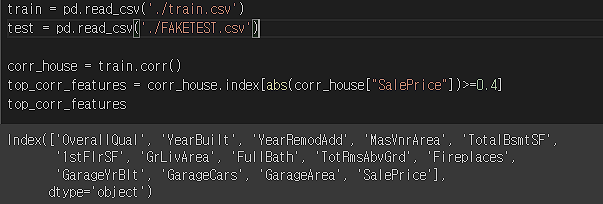
이걸 이쁘게 좀 보자면,
subset=train[['OverallQual', 'YearBuilt', 'YearRemodAdd', 'TotalBsmtSF', '1stFlrSF',
'GrLivArea', 'FullBath', 'TotRmsAbvGrd', 'GarageCars', 'GarageArea',
'SalePrice']]
y = subset['SalePrice']
X = subset.drop(['SalePrice'], axis=1)
reg=LinearRegression()
reg.fit(X,y)
y_train_error = reg.predict(X)
rmse=(np.sqrt(mean_squared_error(y, y_train_error)))
print("RMSE is {}".format(rmse))
해당 지표들와 주택 가격에 대한 선형성을 파악하기 위해서 그림을 그려서 분석해줬다.

사실 OverallQual, YearsBuilt 등은 뭐 ... 예상이 되었던 항목.
차고 관련 항목도 많은데, 개인 차고가 있고 필요한 미국의 주택 형태를 생각해보면 나름 재밌는 지표... 애초에 아파트보다 주택을 선호하는 것 같기도 하고
이렇게 그림들을 보면 GrLivArea 항목(왼쪽에서 7번째)을 보면 거슬리는 두 개의 점(큰 값을 갖는)이 보인다.
train.sort_values(by = 'GrLivArea', ascending = False)[:2]
위의 코딩으로 간단하게 제거해준다. (Outlier 처리)
# 아웃라이어 처리하기(1).
train = train.drop(train[train['Id'] == 1299].index)
train = train.drop(train[train['Id'] == 524].index)그리고 GarageArea 항목에서 Outlier도 처리해준다 (오른쪽에서 두번째, 큰 거 3개를 처리)
train.sort_values(by = 'GarageArea', ascending = False)[:3]
# 아웃라이어 처리하기(2)
train = train.drop(train[train['Id'] == 582].index)
train = train.drop(train[train['Id'] == 1191].index)
train = train.drop(train[train['Id'] == 1062].index)근데 지금 와서 생각해보면 모든 그래프 상단에 공통적으로 등장하는 이상하게 비싼 두 개의 점이 거슬린다..
왜 제거 안해줬지...
그 다음으로 해준 것은 Train과 Test 지표에 대한 분포를 비교해줬다.
이 과정이 필요한 이유는 train data set을 활용해서 모델을 훈련하고 Test data set을 분석하게 되는 데,
두 Data set의 분포가 다르면 Train data set에 맞추어 훈련된 모델은 Test data set을 제대로 분석할 수 없게 된다.
(기출을 겁나 팠는데 기출 변형이 많으면 모델이 당황하게 될 것....)
sns.distplot(train['SalePrice'] , fit=norm); #distplot은 분포에 대한 히스토그램을 만들어준다.
fig = plt.figure()
res = stats.probplot(train['SalePrice'], plot=plt)
plt.show();

위는 Train, 아래는 Test인데 두 데이터의 분포가 꽤 차이가 있는 것을 알 수 있다.
아무튼 이런 식으로 분포가 잘 안되어 있는 지표들을 찾아서 log scale 화 시켜서 분포를 이쁘게 해줬다.
# 3가지 피처, 'SalePrice', '1stFlrSF', 'GrLivArea'에 대해
# log 스케일로 바꾼다.
train["SalePrice"] = np.log1p(train["SalePrice"])
#test["SalePrice"] = np.log1p(test["SalePrice"])
train["1stFlrSF"] = np.log1p(train["1stFlrSF"])
test["1stFlrSF"] = np.log1p(test["1stFlrSF"])
train["GrLivArea"] = np.log1p(train["GrLivArea"])
test["GrLivArea"] = np.log1p(test["GrLivArea"])
지금 와서 생각해보니 모든 지표에다가 해줘도 됐을 것 같기는 한데...
여기서 log1p를 사용한 이유는 np.log(0) 은 -inf의 값을 갖게되므로 오류가 출력이 된다.
log1p(0) = log(1+0) 의 값으로 계산하게 되는데, -inf의 값을 피하게 되어 오류를 피할 수 있다.
전처리는 이제 시작이다 지금은 feature 만 조금 만져줬다
2편에 계속