house price - 2 - 전처리
house price 첫번째 시간은 데이터들을 파악하는 데에 집중했다.
그러다가 문득, 이런 전처리 없이 학습하면 어떻게 될 지 궁금해졌다.
나는 토끼가 좋다
corr_house = train.corr()
top_corr_features = corr_house.index[abs(corr_house["SalePrice"])>=0.5]
top_corr_features
subset=train[['OverallQual', 'YearBuilt', 'YearRemodAdd', 'TotalBsmtSF', '1stFlrSF',
'GrLivArea', 'FullBath', 'TotRmsAbvGrd', 'GarageCars', 'GarageArea',
'SalePrice']]
y = subset['SalePrice']
X = subset.drop(['SalePrice'], axis=1)
reg=LinearRegression()
reg.fit(X,y)
y_train_error = reg.predict(X)
rmse=(np.sqrt(mean_squared_error(y, y_train_error)))
print("RMSE is {}".format(rmse))
또 달라진 게 있다면 상관계수가 0.5 이상인 feature들만 뽑아서 진행하는 것으로...
그리고 y로 Saleprice로, X로 Saleprice를 제외한 나머지 Feature들...
모델은 보통 처음 배우는 모델인 LinearRegression으로 선정하고 실제 Saleprice와 훈련 결과로 나온 Saleprice과 비교해줬다.
이 오차는 rmse로 계산해서 결과를 출력했는데.
37779$의 오차가 있었다.
위의 결과에서 아웃라이어만 처리해주면
# 아웃라이어 처리하기(1).
train = train.drop(train[train['Id'] == 1299].index)
train = train.drop(train[train['Id'] == 524].index)
# 아웃라이어 처리하기(2)
train = train.drop(train[train['Id'] == 582].index)
train = train.drop(train[train['Id'] == 1191].index)
train = train.drop(train[train['Id'] == 1062].index)
subset=train[['OverallQual', 'YearBuilt', 'YearRemodAdd', 'TotalBsmtSF', '1stFlrSF',
'GrLivArea', 'FullBath', 'TotRmsAbvGrd', 'GarageCars', 'GarageArea',
'SalePrice']]
y = subset['SalePrice']
X = subset.drop(['SalePrice'], axis=1)
reg=LinearRegression()
reg.fit(X,y)
y_train_error = reg.predict(X)
rmse=(np.sqrt(mean_squared_error(y, y_train_error)))
print("RMSE is {}".format(rmse))
약 33553$로 오차가 조금 줄은 것을 확인할 수 있었다.
위의 결과에서 똑같이 logscale을 넣으면
# 3가지 피처, 'SalePrice', '1stFlrSF', 'GrLivArea'에 대해
# log 스케일로 바꾼다.
train["SalePrice"] = np.log1p(train["SalePrice"])
#test["SalePrice"] = np.log1p(test["SalePrice"])
train["1stFlrSF"] = np.log1p(train["1stFlrSF"])
test["1stFlrSF"] = np.log1p(test["1stFlrSF"])
train["GrLivArea"] = np.log1p(train["GrLivArea"])
test["GrLivArea"] = np.log1p(test["GrLivArea"])
subset=train[['OverallQual', 'YearBuilt', 'YearRemodAdd', 'TotalBsmtSF', '1stFlrSF',
'GrLivArea', 'FullBath', 'TotRmsAbvGrd', 'GarageCars', 'GarageArea',
'SalePrice']]
y = subset['SalePrice']
X = subset.drop(['SalePrice'], axis=1)
reg=LinearRegression()
reg.fit(X,y)
y_train_error = reg.predict(X)
rmse=(np.sqrt(mean_squared_error(np.expm1(y), np.expm1(y_train_error))))
print("RMSE is {}".format(rmse))
29276$로 오차가 더 줄은 것을 확인할 수 있다.
사실, 전처리 과정은 여기서 끝나지 않았는데.

1탄에서 어떤 feature들이 있는지를 확인했는데, 각 sample의 숫자가 다른 것을 확인할 수 있다.
결측치 처리를 제대로 해주어야하는데, 평균값 혹은 해당 feature에서 빈도수가 많은 값을 넣어주거나 결측치가 너무 많으면 해당 feature를 빼거나한다.
먼저 결측치에 대한 비율을 출력해보자.
allna = (train.isnull().sum() / len(train))
#allna = allna.drop(allna[allna == 0].index).sort_values(ascending=False)
allna = allna.sort_values(ascending=False)
plt.figure(figsize=(20, 4))
allna.plot.bar(color="black")
plt.title('Missing values average per column : train set', fontsize=25, weight='bold' )
plt.axhline(0.1, 0, 1, color='red', linestyle='solid', linewidth=2)
plt.show()
allna = (test.isnull().sum() / len(test))
#allna = allna.drop(allna[allna == 0].index).sort_values(ascending=False)
allna = allna.sort_values(ascending=False)
plt.figure(figsize=(20, 4))
allna.plot.bar(color="black")
plt.title('Missing values average per column : test set', fontsize=25, weight='bold' )
plt.axhline(0.1, 0, 1, color='red', linestyle='solid', linewidth=2)
plt.show()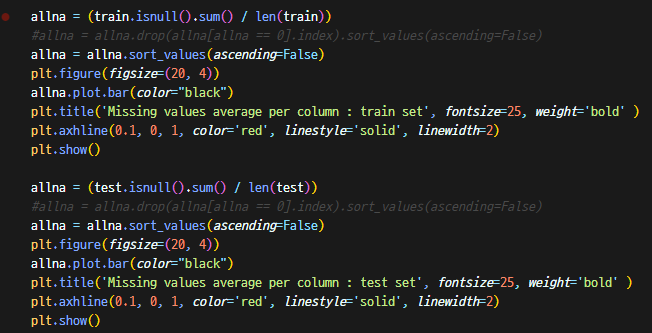
결측치의 비율이 10%가 넘는 feature 6개가 된다.

일정 % 이상이 아닌 것들에 대해서 자세히 보기 위해서..


또 28개는 위와 같은 약간의 결측치가 존재한다.
이 결측치들을 어떻게 처리해야하나 고민했는데, 먼저 10% 항목에 대해서...
PoolQC = 수영장의 퀄리티를 의미한다. NaN일 경우, 수영장이 없는 주택을 의미한다. (대부분 없다)
MiscFeature = Miscellaneous feature not covered in other categories (다른 범주에서 다루지 않은 기타 기능, 엘리베이터, 테니스코트 등 따위가 포함되어 있다. 대부분 없음)
Fence = 펜스의 퀄리티를 의미한다. NaN일 경우 펜스가 없다
FireplaceQu = 벽난로의 퀄리티를 의미한다.
LotFrontage = 집과 도로까지의 직선 거리? (정확히는 어떤 문에서 나가는 그런 직선 거리를 의미했던 것으로 기억한다.
Alley = 골목길이 있는 지? 소유의 골목길이면 대문에서 현관까지의 길을 의미? 한다고 생각했다. (잔디, 포장 혹은 없음..)
주택임을 고려할 때, Alley를 제외한 나머지 5 항목은 제거해줬다. Alley 제외 나머지는... 웬만해서는 없을 것이기에 none으로 해줘도 되지만, 이게 실제로 없는 건지 혹은 정말 누락된건지 알 수 없기 때문에 제거해줬다. Alley는 누락보다는, 실제로 없다고 보는 것이 자연스럽다. (서민의 집을 생각해볼 때 주택의 현관을 열자마자 길로 연결되는 그런.. 집?)
Lotfontage는 숫자형 변수인데 마땅히 값을 넣기 애매... 해서 뺐고 Alley는 None으로 처리해줬다.
아, 결측치 처리를 해주기 앞서 Train과 test 둘 다 합쳐서 처리를 해줘야한다.
#nan 값 처리를 train과 test 파일에 걸쳐서 하기 위해 concat으로 합쳐준다.
# 이때 나중에 다시 나눠야하기 때문에 train의 길이를 저장한다.
# train 데이터의 행 개수 추출
len_train = train.shape[0]
# train과 test 데이터의 'SalePrice' 피처 추출
y_reg = train['SalePrice']
#y_test_reg = test['SalePrice']
# test 데이터의 인덱스(1461부터 2919) 추출
Id = test['Id']
# train과 test 데이터 병합
df_all = pd.concat([train,test])
# train과 test 데이터에 있던 인덱스 제거
del df_all['Id']
# In these features, NAN means none
# nan 처리!
# 손실된 데이터가 너무 많은(몇 % 이상) 피처들을 아예 제거하기.
df_all = df_all.drop(['PoolQC'], axis=1)
df_all = df_all.drop(['MiscFeature'], axis=1)
df_all = df_all.drop(['Fence'], axis=1)
df_all = df_all.drop(['FireplaceQu'], axis=1)
df_all = df_all.drop(['LotFrontage'], axis=1)
# 문자형 피처들의 손실된 데이터를 'None'으로 채우기 / 지하실, 차고가 NaN 보다는 없는 게 더 자연스러움
df_all["Alley"] = df_all["Alley"].fillna("None")
df_all['BsmtQual'] = df_all['BsmtQual'].fillna('None')
df_all['BsmtCond'] = df_all['BsmtCond'].fillna('None')
df_all['BsmtExposure'] = df_all['BsmtExposure'].fillna('None')
df_all['BsmtFinType1'] = df_all['BsmtFinType1'].fillna('None')
df_all['BsmtFinType2'] = df_all['BsmtFinType2'].fillna('None')
df_all['GarageType'] = df_all['GarageType'].fillna('None')
df_all['GarageFinish'] = df_all['GarageFinish'].fillna('None')
df_all['GarageQual'] = df_all['GarageQual'].fillna('None')
df_all['GarageCond'] = df_all['GarageCond'].fillna('None')
# 숫자형 피처들의 손실된 데이터를 0으로 채우기 / 지하실, 차고가 NaN 보다는 없는 게 더 자연스러움
df_all['BsmtFinSF1'] = df_all['BsmtFinSF1'].fillna(0)
df_all['BsmtFinSF2'] = df_all['BsmtFinSF2'].fillna(0)
df_all['BsmtUnfSF'] = df_all['BsmtUnfSF'].fillna(0)
df_all['TotalBsmtSF'] = df_all['TotalBsmtSF'].fillna(0)
df_all['BsmtFullBath'] = df_all['BsmtFullBath'].fillna(0)
df_all['BsmtHalfBath'] = df_all['BsmtHalfBath'].fillna(0)
df_all['MasVnrArea'] = df_all['MasVnrArea'].fillna(0)
df_all['GarageYrBlt'] = df_all['GarageYrBlt'].fillna(0)
df_all['GarageCars'] = df_all['GarageCars'].fillna(0)
df_all['GarageArea'] = df_all['GarageArea'].fillna(0)
# 당연히 있어야 하는 손실된 데이터를 평균값(?)으로 채우기
df_all['MSZoning'] = df_all['MSZoning'].fillna(df_all['MSZoning'].mode()[0])
df_all['Exterior1st'] = df_all['Exterior1st'].fillna(df_all['Exterior1st'].mode()[0])
df_all['Exterior2nd'] = df_all['Exterior2nd'].fillna(df_all['Exterior2nd'].mode()[0])
df_all['MasVnrType'] = df_all['MasVnrType'].fillna(df_all['MasVnrType'].mode()[0])
df_all['Electrical'] = df_all['Electrical'].fillna(df_all['Electrical'].mode()[0])
df_all['KitchenQual'] = df_all['KitchenQual'].fillna(df_all['KitchenQual'].mode()[0])
df_all['Functional'] = df_all['Functional'].fillna(df_all['Functional'].mode()[0])
df_all['SaleType'] = df_all['SaleType'].fillna(df_all['SaleType'].mode()[0])
이 다음에 Feature들을 합쳐주거나 이진화 피쳐들을 만든다.
1-1. 합쳐주는 것을 왜 해야하는가?
=> 실생활 측면에서 분석해보면, 총 평수라는 개념이 있을 것이고, 총 면적이라는 개념이 존재한다. 이와 비슷한 구조의 Feature를 만들어주는 것이다. 예를 들어, 해당 데이터에는 1층의 면적과 2층의 면적이 따로 따로 존재하는데, 총 면적의 측면에서 Feature들을 합쳐준다면? 총 면적이라는 새로운 특성이 나타나게 된다.
이를 테면, 1층의 면적이 100평에 가깝고, 2층의 면적은 다락방 겸 테라스 용도인 20평의 큰 집과 1층/2층 모두 20평 남짓한 집을 상상해보자. 이런 경우에는 총 면적으로 접근하는 것이 더 좋은 상관관계인 것을 확인 할 수 있을 것이다.
1-2. 어떻게 하는가?
비슷한, 공통된 특성을 갖는 특성들을 합쳐준다. 예를 들면, 지하실 면적 = 지하1층 면적 + 지하2층 면적 뭐 이런식으로?
2-1. 이진화 피쳐를 왜 만들어야하는 가?
=> 사실 'Area' 라는 지표보다 그 것이 있음이 큰 영향을 미치는 주택이 있을 것이다. 예를 들면 수영장이 그렇고, 지하실이 그렇다. PoolArea라는 지표보다는 'Including Pool' 이라는 지표로 접근해야 좋을 수 있다.
2-2. 어떻게 하는가?
lambda x: 1 if x > 0 else 0으로 해줄 수 있다.
# One Hot Encoding을 하기위해 라이브러리를 불러오기.
# from sklearn.preprocessing import OneHotEncoder
# train과 test 데이터를 합친 df_all을 one_hot_encoding으로 복사하기.
one_hot_encoding = df_all.copy()
# 'get_dumies' 함수로 새로운 피처들 생성
# 이 때, 함수 'get_dumies'는 벡터라이즈이다.
# 한편, one hot encoding은 사용하지 않았다.(라이브러리 불러놓고 다른 함수 씀)
# get_dumies와 one hot encoding는 동일한 원리를 사용하지만
# get_dumies는 숫자형 데이터는 백터라이즈를 하지 않는다.
one_hot_encoding = pd.get_dummies(one_hot_encoding)
# 숫자형 피처들 중에 공통된 특성을 갖고 있는 피처들이 있다.
# 그런 피처들을 하나로 합친 새로운 피처들을 생성해준다.
one_hot_encoding['Total_sqr_footage'] = one_hot_encoding['BsmtFinSF1'] + one_hot_encoding['BsmtFinSF2'] + one_hot_encoding['1stFlrSF'] + one_hot_encoding['2ndFlrSF']
one_hot_encoding['Total_Bathrooms'] = one_hot_encoding['FullBath'] + one_hot_encoding['HalfBath'] + one_hot_encoding['BsmtFullBath'] + one_hot_encoding['BsmtHalfBath']
one_hot_encoding['Total_porch_sf'] = one_hot_encoding['OpenPorchSF'] + one_hot_encoding['3SsnPorch'] + one_hot_encoding['EnclosedPorch'] + one_hot_encoding['ScreenPorch'] + one_hot_encoding['WoodDeckSF']
one_hot_encoding['TotalHouse'] = one_hot_encoding['TotalBsmtSF'] + one_hot_encoding['1stFlrSF'] + one_hot_encoding['2ndFlrSF']
one_hot_encoding['TotalArea'] = one_hot_encoding['TotalBsmtSF'] + one_hot_encoding['1stFlrSF'] + one_hot_encoding['2ndFlrSF'] + one_hot_encoding["GarageArea"]
one_hot_encoding['GrLivArea_OverallQual'] = one_hot_encoding['GrLivArea'] * one_hot_encoding['OverallQual']
one_hot_encoding['LotArea_OverallQual'] = one_hot_encoding['LotArea'] * one_hot_encoding['OverallQual']
# 이진화 피처를 만든다.
one_hot_encoding['haspool'] = one_hot_encoding['PoolArea'].apply(lambda x: 1 if x > 0 else 0)
one_hot_encoding['hasgarage'] = one_hot_encoding['GarageArea'].apply(lambda x: 1 if x > 0 else 0)
one_hot_encoding['hasbsmt'] = one_hot_encoding['TotalBsmtSF'].apply(lambda x: 1 if x > 0 else 0)

이때, 사용한 함수가 get_dummies 인데 원래는 다른 기능을 제공한다.
바로 가변수를 만들어주는 함수이다. 다음 글을 참조하면 더 좋을 것 같다.
[pandas] pd.get_dummies() : 데이터전처리/가변수 만들기
[pandas] pd.get_dummies() : 가변수 만들기 머신러닝을 할 때 기계가 이해할 수 있도록 모든 데이터를 수치로 변환해주는 전처리 작업이 필수적이다. 예를들어, 숫자가 아닌 object형의 데이터들이
devuna.tistory.com
전처리가 끝났으니, 다시 Train과 Test 데이터로 나누어보자.
# 이제 작업을 마친 데이터들을 다시 train과 test로 나눠준다.
one_hot_encoding_train = one_hot_encoding[:len_train]
one_hot_encoding_test = one_hot_encoding[len_train:]
# train에서 상관계수가 50% 이상인 피처들을 추출한다.
corr_house = one_hot_encoding_train.corr()
top_corr_features = corr_house.index[abs(corr_house["SalePrice"])>=0.5]
top_corr_features
상관계수가 0.5 이상인 변수들이 꽤 많이 늘어났음을 알 수 있다.
subset=one_hot_encoding_train[['OverallQual', 'YearBuilt', 'YearRemodAdd', 'TotalBsmtSF', '1stFlrSF',
'GrLivArea', 'FullBath', 'TotRmsAbvGrd', 'GarageCars', 'GarageArea',
'SalePrice', 'ExterQual_Gd', 'ExterQual_TA', 'Foundation_PConc',
'KitchenQual_TA', 'Total_sqr_footage', 'Total_Bathrooms', 'TotalHouse',
'TotalArea', 'GrLivArea_OverallQual']]
y = subset['SalePrice']
X = subset.drop(['SalePrice'], axis=1)
reg=LinearRegression()
reg.fit(X,y)
y_train_error = reg.predict(X)
rmse=(np.sqrt(mean_squared_error(np.expm1(y), np.expm1(y_train_error))))
print("RMSE is {}".format(rmse))
결과는 아까에 비해서 더 좋은 24960$ 이다.
아, 설명 안하고 넘어간 부분이 있다.
rmse에 대한 부분인다.
rmse를 np.sqrt로 표현하고 있는 것은 맞지만, np.expm1으로 하고 있다
이유는 로그 스케일에 있다. 아까 saleprice를 좀 표준화해주는 과정을 하면서 np.log1p 로 해줬다.
그 것에 대한 역산으로 1을 빼주고 exp를 씌워준 식을 표현하기 때문에 해당 식으로 해줬다.