최근에 ML/AI 쪽에 관심이 생기면서 책을 사서 공부까지 해보고 있는데, 옛날에는 import 해서 다른 학습 모델들을 가져다 썻었던 것에 비해서 책의 내용은 직접 구현하고 있으니 괴리감이 있었다.
기억이 희석되고 대체되기 보다는 기존의 내가 알던 것과 새로운 것을 비교해가면서 공부하려고 한다.
Untitled3 이 없는 이유는... wine 관련 데이터에 대한 분석인데, 내용은 이전과 대부분 같기 때문이다.
---------------------------------------------------------------------------------------------------------------------------------------------------------
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
raw_data = pd.read_excel('titanic.xls')
raw_data.info()언급된 DataSet은 Kaggle 에서 구할 수 있다. (와 코드블럭 괜찮다)
목표는 어떤 사람에 대한 정보를 입력했을 때 그 사람의 생존율은 어떻게 되는지에 대한 여부이다.

위와 같은 출력결과를 얻을 수 있다. .info() 메서드는 어떤 feature들이 있는지 보여준다.
데이터형도 같이 출력되는데, object는 흔히 생각하는 단어형태라고 보면 될 듯 하다.
name이나 sex 같은 간단한 것들은 넘어가고 Feature들을 정리해보자면
- PClass : n등석 (1등석(1), 2등석(2) 등)
- Survived : 생존(1) / 사망(0)
- Sibsp : 타이타닉호에 동승한 자매 / 배우자의 수
- Parch : 타이타닉 호에 동승한 부모 / 자식의 수
- Ticket : 티켓 번호
- Fare : 승객 요금
- Cabin : 방 호수
- Embarked : 탑 승지를 의미한다고 하는데, 셰르부르(C) / 퀸즈타운(Q) / 사우스햄튼(S)
raw_data.describe()
전체 데이터의 대략적인 분포를 확인할 수 있는 메서드, .Describe()
사실 그렇게 막 자주 사용하는 메서드는 아니긴하다.
raw_data.corr()
위와 같이 상관계수에 대해 먼저 파악해보자. 우리의 Target은 Survived 이므로 2번째 행을 집중해서 보면 된다.
plt.figure(figsize=(10,10))
sns.heatmap(raw_data.corr(),linewidth=0.01,square=True, annot=True,linecolor='black')
plt.show()
이런 식으로 시각화를 취할 수 있다. PClass. 즉, 좋은 등석(숫자 낮으므로)일수록 생존할 확률이 높았음을 알 수 있다.
근데 사실 여기서 함정이 있다. 바로 "Age" 인데, Age의 분포도가 다른 변수들에 너무 넓다.
다른 변수가 0~3 정도라면 Age은 0~100 이니까..
raw_data['age_cat'] = pd.cut(raw_data['age'], bins=[0,7,15,30,60,100],
include_lowest=True, labels=['baby','teenage','young','adult','old'])
raw_data.head()이렇게 pd.cut() 을 통해서 나이를 'baby','teenage','young','adult','old'로 나눠서 처리해보자.
plt.figure(figsize=[10,5])
sns.barplot('age_cat', 'survived', data=raw_data)
plt.show()
위와 같은 시각화를 취할 수 있다.
다른 것들도 시각화를 해보자면
plt.figure(figsize=[10,5])
sns.barplot('sex', 'survived', data=raw_data)
plt.show()
ㅠㅠ 영화에서도 아이와 여자를 먼저 태우라고 했는데, 그 말이 사실 이었나보다. 생존한 정말 많은 사람들이 여자분들이다.
plt.figure(figsize=[10,5])
sns.countplot('sex', hue='survived', data=raw_data)
plt.show()
sns.countplot()은 data로부터 'sex'의 카운트를 하고, hue는 survived로 구분하여 표시하는 것이다. 이런 식으로 전체 수를 파악할 수도 있다.
여기서 한가지 작업을 더 해줬는데, 아까 좋은 등석일수록 생존할 확률이 높다는 것을 확인할 수 있었다.
그렇다면, 귀족에 대해서도 구분할 수 있다.
그것은 타이타닉 데이터의 이름에서 파악할 수 있는데,
raw_data['name'][0:5]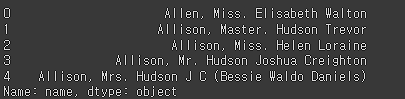
여기서 보면은 가운데 글자인 Miss / Master / Mr. 등으로 호칭이 나타나있다.
raw_data['title'] = raw_data['name'].map(lambda x : x.split(',')[1].split('.')[0].strip())
titles = raw_data['title'].unique()
titlesmap 함수는 데이터에 적용시킬 함수를 만들 수 있고, lambda는 데이터 x에 대하여 취하는 작업을 의미한다.
x.split(',')[1].split('.')[0].strip() 은
x.split(',') [1] => ,을 기준으로 나눈 것 중 뒤의 것을 취하고
.split('.')[0] => .을 기준으로 나눈 것 중 앞의 것을 취한다.
.strip() 앞 뒤의 스페이스를 없애고 순수히 그 문자열만 취한다.

이렇게 결과가 나왔다.
raw_data['title'] =raw_data['title'].replace('Mlle','Miss')
raw_data['title'] =raw_data['title'].replace('Ms','Miss')
raw_data['title'] =raw_data['title'].replace('Mme','Mrs')
Rare = ['Lady', 'the Countess', 'Countess', 'Capt', 'Master', 'Col', 'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona']
for each in Rare:
raw_data['title'] = raw_data['title'].replace(each, 'Rare')
raw_data['title'].unique()'title' 이라는 Feature를 만들어주었으며 특별한 귀족 호칭의 경우엔 For문을 통해서 'Rare'라고 표기했다.
또한 sex가 현재 Male, Female로 구분되어 있으므로 숫자로 바꿔주었다.
tmp = []
for each in raw_data['sex']:
if each == 'female':
tmp.append(0)
elif each == 'male':
tmp.append(1)
else:
tmp.append(np.nan)
raw_data['sex'] = tmp
raw_data.head()
그리고 이름도 그리 중요한 데이터는 아니고 분석에 있어서 의미없을 수 있는(다른 Feature들에 비해 숫자가 부족하거나 NaN인) 것들을 빼고 새로운 데이터프레임을 취해준다.
titanic = raw_data[['survived', 'pclass', 'sex', 'sibsp', 'parch', 'fare', 'age']]
titanic.head()
titanic.info()
여전히 숫자가 비어있는 항목들이 보인다. 갯수를 맞춰줘야한다.
titanic = titanic[titanic['age'].notnull()]
titanic = titanic[titanic['fare'].notnull()]
titanic.info()
해석해보자면, Age와 Fare의 notnull(=비어있지 않은)인 애들만 반환해서 titanic에 덧입힌 것이다.
보통 이 과정을 결측치처리라고 하는데, 결측치없이 순수히 모든 Feature가 살아있는 데이터를 상대로 예측을 해야 더 좋은 결과가 나온다.
결정나무로 모델을 만들고 예측을 진행해보자
from sklearn.model_selection import train_test_split
y=titanic['survived']
X=titanic.drop(['survived'], axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=13)
from sklearn.tree import DecisionTreeClassifier
tree_clf = DecisionTreeClassifier(max_depth=3,random_state=13)
tree_clf.fit(X_train, y_train)훈련 / 테스트 데이터로 나누고 결정나무 Classifier를 불러와서 진행한다.
Classifier 는 분류기 모델로 보통 0 / 1 등 Digit한 데이터에 대한 예측을 할 때 사용된다.
Regression 는 회귀 모델로 보통 0 ~ 1 등 Analog 한? 어찌보면 0, 1 등으로 명확히 구분할 수 없는, 예측값이 정수가 아닌(True or False, Class 1 or 2 와 같은 문제가 아닌 집 값 등) 예측을 할 때 사용된다.
아무튼 이를 시각화 하면 (max_depth=3을 주목해보자)
from graphviz import Source
from sklearn.tree import export_graphviz
from IPython.display import SVG
graph = Source(export_graphviz(tree_clf, out_file=None, feature_names=X_train.columns, class_names = ['Unsurvived', 'Survived'], rounded = True, filled = True ))
display(SVG(graph.pipe(format='svg')))

좀 복잡한 결정나무가 완성된다.
모델을 만들었으니 평가를 진행해보자.
from sklearn.metrics import accuracy_score
y_pred_tr = tree_clf.predict(X_train)
y_pred = tree_clf.predict(X_test)
print(accuracy_score(y_train, y_pred_tr))
print(accuracy_score(y_test, y_pred))
약 훈련 데이터 셋에 관하여 80%, 테스트 데이터 셋에 고나하여 78% 정도의 적중률을 보인다.
이제 내가 직접 데이터를 만들어서 예측해보자

파악 완료.

흠.. 이정도면.. 어차피 살았을듯..? 컴백.. 잭.. 컴백....
결정나무는 또 어떤 feature가 가장 중요한지에 대해서도 Return 하는 메서드가 존재한다.
major_feature =tree_clf.feature_importances_
major_feature
아무래도 성별이 가장 많은 비중을 차지한다.
import numpy as np
sort_feature = np.argsort(major_feature)
bar_pos = np.arange(sort_feature.shape[0])+0.5
plt.figure(figsize=(8,8))
plt.barh(bar_pos, major_feature[sort_feature], align='center')
plt.yticks(bar_pos, X_train.columns[sort_feature])
plt.show()
실제로 plot으로 표시하니 더 크게 느껴진다.
여기까지 진행을 했다. 아직까진 결정나무 위주.
'Coding' 카테고리의 다른 글
| house price - 2 - 전처리 (0) | 2022.08.15 |
|---|---|
| house price - 1 - 파악 (0) | 2022.08.14 |
| 과거 정리 - Untitled2.ipynb(Boston, .corr(), rmse, scatter, .drop) (0) | 2022.06.28 |
| 과거 정리 - Untitled1.ipynb (Iris, Decision Tree) (0) | 2022.06.27 |
| 과거 정리 - Untitled0.ipynb (import, plt 등) (0) | 2022.06.27 |



