*편의를 위해 코드 부분은 캡쳐로 대체*
회사 내 교육으로 CNN 등 Deep Learning에 대해서 배웠다.
마지막에 Time Series Classification을 CNN 등으로 분류하는 프로젝트를 진행했다.
사실, 그 전에 다른 문제들도 직접 풀어보긴 했지만.... Time Series 문제들에 대해서 많은 시간을 할애했기에 해당 문제들에 관해서만 정리를 해본다.

실습이 colab+구글 드라이브로 진행됐기에 필요한 구글 드라이브 마운트 과정.

먼저, 해당 데이터의 label을 확인해본다.

0은 y축으로 좀 고르게 분포되어 있고 1은 y축으로 고르지 못하고 들쑥 날쑥하다. (Min-Max를 주목해보자_)
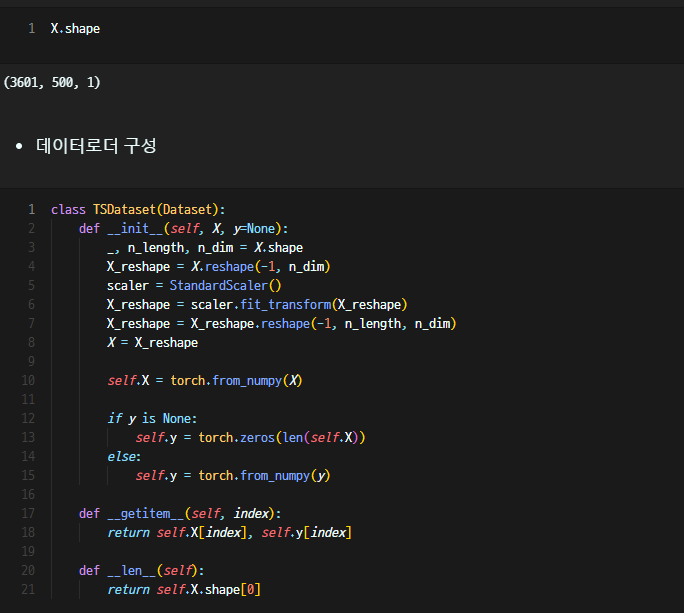
그리고 X.shape를 통해 차원을 확인해줬는데, 차원을 미리 파악하는 것은 꽤 중요하다. (CNN과 같은 layer 만들어주는 것에서 차원 맞춰주는 과정이 중요)
데이터로더를 구성해주고...
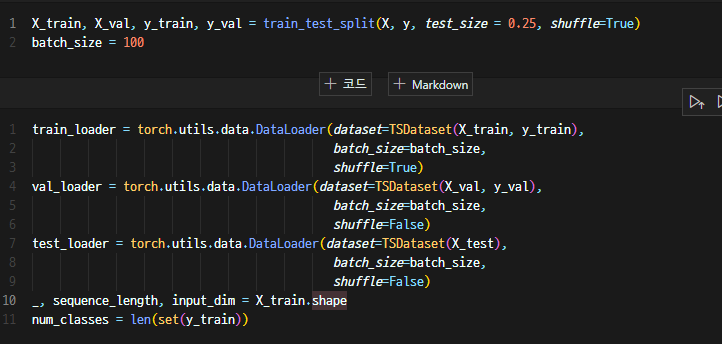
test를 위해 solit도 한다. 그리고 아까 구성한 DataLoader를 활용해 데이터를 구분한다.
batchsize와 shufflet을 설정한다.

FC는 Fully Connected의 줄임말로 기억한다.
CNN 구조는 다음과 같다. 시계열이라 Conv1D 등 1D 함수를 사용했다.
Layer 1
Channels : 1 => 32 (Kernel_size 3, padding 1)
이후 Batch Normalization으로 overfitting을 막으려 했고, ReLU, Max pooling을 하고 다음 레이어로.

Layer 2
Channels : 32 => 64 (Kernel_size 3, padding 1)
나머지 구성은 위와 똑같다.

그리고 LSTM Layer를 추가해서 성능을 올려줬다.
해당 실습 데이터의 양이 그렇게 많지 않아서 단순 3 layer로도 성능이 나쁘지는 않았지만, CNN 2 + LSTM 1 이렇게 3개의 조합이 제일 성능이 잘나왔었던 것 같다.
input과 output size는 사실 더 늘려주고 싶었지만, 컴퓨터 성능의 문제로... (Cuda out of memory 에러가 자꾸 나왔다)
그리고 dropout. 이 역시 Overfitting을 해결하기 위해서 네트워크의 weight를 0으로 만들어주는 기법이다.
지금 와서 생각해보니 데이터가 적었고, 데이터를 좀 섞거나 해서 Generate 하거나 test 데이터도 나중에 추가해서 학습해주는 등 하여 데이터 수를 보충해주는 방향도 고려해볼 걸 그랬다는 생각이 든다.
그리고 fc1/fc2/fc3/fc4는 output dimension으로 보내주기 위해서 만들었다.
나눠준 이유 및 ReLU가 있는 것은, 8000 -> num_classes 로 가는 것보다 여러 구조를 거쳐서 줄여나가는 것이 더 성능이 좋기 때문.
Forward 쪽은 차원 맞추는 게 쬐끔 어려웠다.
들어온 데이터의 shape는 batch/length/dim, 1d의 요구 shape는 batch/channel/length 였기 때문에 처음에 Transpose를 해줬다.
그 다음에 다시 lstm에 넣기 위해 tranpose를 해줬고, Contiguous로 다시 ouput shape로 바꿔서 linear layer에 전달..
* Contiguous는?
view나 transpose는 기본적으로 메모리를 재할당하지 않는다. (둘 모두 차원을 바꿔주는)
때문에, 행렬을 비롯해 포인터 연산 시 오류가 발생한다.
객체의 사이즈가 맞지 않거나, 값들이 연속되어 있지만 주소들은 옛날 주소로 되어있기 때문이다.
Contiguous는 이런 문제를 해결하기 위해 새로운 메모리 공간을 할당하고 복사해 재배열 해준다.(연속성을 갖도록)

그리고 만들어본 오토엔코더
기본구조 없이 내가 직접 만들어본거여서 그런지 심플 CNN 구조 처럼 됐다.

예전에 하던 프로젝트가 생각나서 만든 앙상블. 예전에는 모델을 하나하나 다 만들어서 *0.n 을 하고 합해주는 형식인데,
나름 구글링해서 pytorch 들의 함수들을 사용해서 만들었다. Modulelist가 있고, append를 취한 다음에, stack -> mean을 사용해줘서- 앙상블 모델을 구현할 수 있었다.

하이퍼 파라미터 설정과 모델, Optimizer 설정
같이 교육들은 다른 분들 모델 발표 들어보니까 하이퍼 파라미터 값들만 엄청 깎았더니 좋은 결과를 얻으신 분이 많았다.
나도 좀 더 트라이 해볼걸... 값을 많이 조정하긴 했지만 계속해서 새로운 모델을 찾았던 것 같다.
모델은 아까 만든 Ensemble 모델을 호출.
criterion은 해당 프로젝트 loss 값 기준이 CrossEntropyLoss 였고, Optimizer는 Adam.
어떤 opitmizer를 고를지 모르겠다면, Adam을 일단 써보라는 강의 내용이 기억에 남는다. weight_decay는 과적합을 해결하기 위해 추가해준 부분.

다음은 학습부분. 이 부분의 구조를 내것으로 만들고 싶었다.
학습 후 실제 값과 비교하여 다시 학습하는 Backprogation 구조이고, correct는 y_pred.max(dim=1)[1] == y 로
일치하는 것을 찾고 total에 더한 다음 정답율을 살펴본다.
*torch.no_grad()는 찾아보니까 gradient 없이(수정없이) 모델을 진행하는 것.
Cuda의 부하도 줄여주고, 저 정답율 부분이 아니라 loss.backward()로 학습되기 때문. 사실, 이 부분은 학습 중간중간 학습의 추이를 살펴보기 위함이다.
그리고 하단 부분은 Validation 부분. 그래서 val_loader로 따로 호출한다.

나머지는 이제 result로 출력하는 부분.
차근차근 하나씩.. 살펴보면서 내 것으로 만드려고 한다.
'Coding' 카테고리의 다른 글
| house price - 3 - 모델 (0) | 2022.08.20 |
|---|---|
| house price - 2 - 전처리 (0) | 2022.08.15 |
| house price - 1 - 파악 (0) | 2022.08.14 |
| 과거 정리 - Untitled4.ipynb(타이타닉, 결정나무, pd.cut(), 결측치 처리 등) (0) | 2022.07.03 |
| 과거 정리 - Untitled2.ipynb(Boston, .corr(), rmse, scatter, .drop) (0) | 2022.06.28 |



